
パナソニックHD 未来の動作を予測
パナソニックR&Dカンパニー オブ アメリカ(PRDCA)、およびパナソニック ホールディングス(パナソニックHD)は、スタンフォード大学の研究者らと共同で、一人称視点の映像や頭部軌道から、現在の動作推定や未来の動作予測を可能にするAI技術「UniEgoMotion」を開発したと発表した。
近年、一人称視点カメラやスマートグラスなどの映像を記録できるデバイスの登場により、ユーザー自身の視点から動作を理解・予測する技術への期待が高まっている。一方で一人称視点動画や頭部軌道からの動作推定は技術的に非常に困難で、三人称視点の画像情報や周辺のシーン情報が追加で必要な場合が多く、実用化においては課題があった。
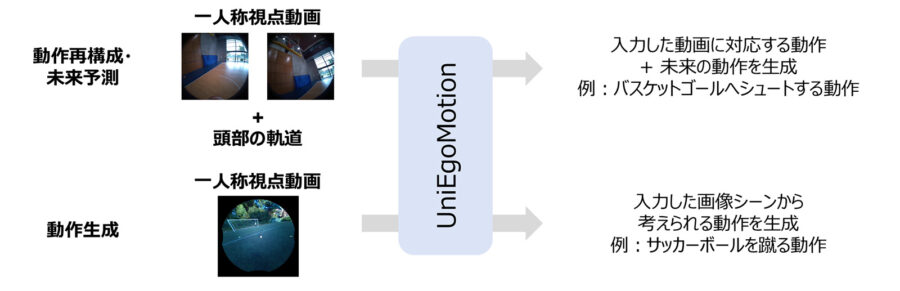
今回、開発した「UniEgoMotion」は、従来の三人称視点やシーン情報に依存しない新たなアプローチにより、一人称視点動画や頭部の軌跡から高精度な3D動作の再構成・予測・生成を実現した。
同技術は、先進性が国際的に認められ、AI・Computer VisionのトップカンファレンスであるIEEE/CVF International Conference on Computer Vision (ICCV)2025に採択された。2025年10月19日から2025年10月23日までアメリカ ハワイで開催される本会議で発表された。
PRDCAとパナソニックHDでは、一人称視点動作モデリングに関する研究に取り組んでいる。昨今、ウェアラブルデバイスやスマートグラスの普及により、ユーザー視点の一人称視点動画からの動作解析や予測を行うニーズが急速に高まっている。しかし一人称視点の動画ではユーザーの身体の一部しか映らないことや、カメラの動きの影響から、現実世界での高精度な動作推定が困難だった。
この課題を解決することは、ユーザーに最適化された動作支援やVR/AR分野への応用の観点から重要だと考えられている。しかし、従来の一人称視点動画を用いた動作推定では、三人称視点の広いシーン情報や3D点群・メッシュなどの明示的な3Dシーン情報を必要とし、実運用には多くの制約があった。
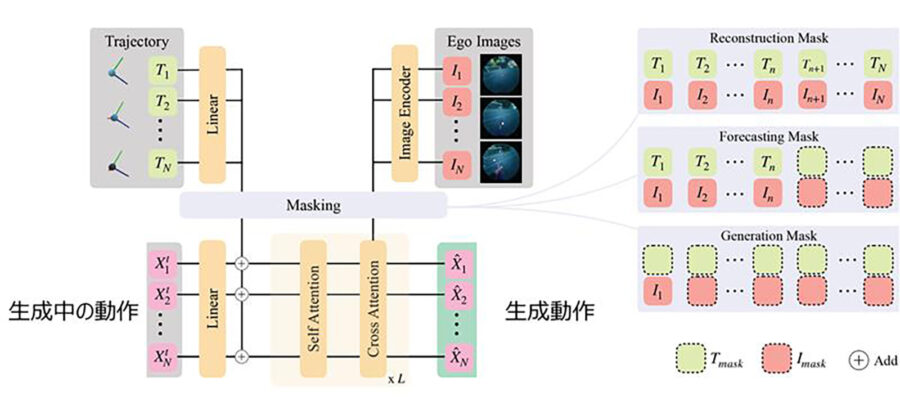
こういった課題を解決する手段として、「UniEgoMotion」は、3Dシーン情報に依存せずに、ウェアラブルデバイスから得られる一人称視点動画と頭部軌道の情報だけで動作を再構成・予測・生成できる統合型モーション拡散モデルを提案した。頭部のウェアラブルデバイスの使用と親和性が高い頭部中心の動作表現の導入や、画像特徴抽出に優れたDINOv2ベースの画像エンコーダを活用することで、従来法を上回る精度と汎用性を実現している。UniEgoMotionは、学習時に動画や頭部軌道の情報の一部をマスキングする手法を採用しており、これにより「現在の動作の推定」だけでなく、「未来の動作の予測」や「新しい動作の生成」も1つのAIモデルで実現している。
評価実験では、一人称視点の映像や頭部軌道から現在の動作を推定する「動作の再構成」のタスクについて既存手法と比較を行い、ポーズの再現精度や動作の自然さを示す評価指標で従来手法を上回る精度を達成した。
今回開発した「UniEgoMotion」は、一人称視点動画や頭部軌跡から高精度な3D動作再構成・予測・生成を1つのモデルで統合的に実現する世界初の統合型モーション拡散モデル。この技術は現場作業可視化・効率化の範囲拡大への活用に加えて、リアルタイム動作解析や、現場作業支援、リハビリ・ヘルスケア分野での動作モニタリングなど、幅広い事業領域での活用が期待されている。
※DINOv2―画像から高品質な画像特徴を抽出できる大規模なモデル

この記事を書いた記者
- 放送技術を中心に、ICTなども担当。以前は半導体系記者。なんちゃってキャンプが趣味で、競馬はたしなみ程度。



